Memory Management
One of the biggest confusing factors on Spark is how to manage the memory. Proper tuning requires a deep understanding of both Spark and JVM memory allocation.
Reference: http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/
The Basic Structure
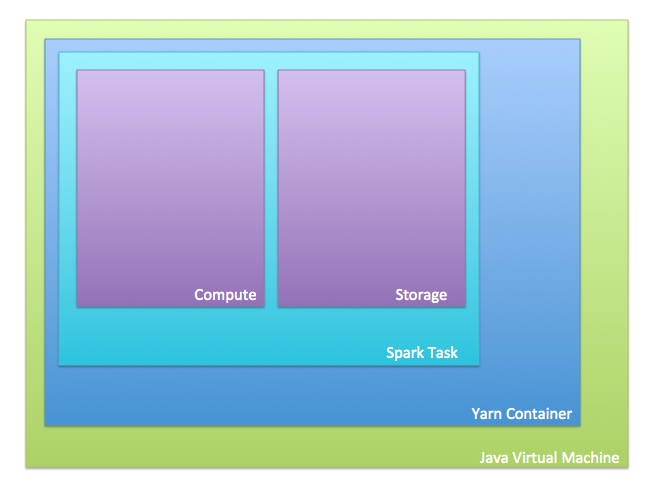
There are 4 levels of memory to tune in Spark:
- JVM
- Yarn Container
- Spark Task
- Compute vs. storage
JVM options:
reference: https://docs.oracle.com/cd/E19900-01/819-4742/abeik/index.html
The JVM level is controlled on Spark session launch with the -X... commands the most commonly set
-Xmx = maximum JVM memory
-Xms = minimum JVM memory; this is useful in that it avoids the cost of reallocating JVM memory if you know you'll need a lot.
-XX:+UseGIGC = set the garbage collector to the newer (and faster)
In addition, the JVM itself is a complicated tangle of memory allocations.
- Split into heap and off-heap
In heap, there are a hierarchy of different memory levels
Generations: young and old
- garbage collection
- within young generation is fast
- between generations is slow
young: temporary
- Buckets:
- Eden
- first point of entry
- Survivor
- Referenced variables moved here when Eden fills up and GC happens
- 2 survivor buckets
- one empty and one full
- when GC is done, the variables to move from Eden are combined with the variables in full survivor and stored in empty survivor.
- Eden
- Buckets:
old: tenured / permanent
- Must be at least as big as young
- Garbage collection from young to old is slow
- garbage collection
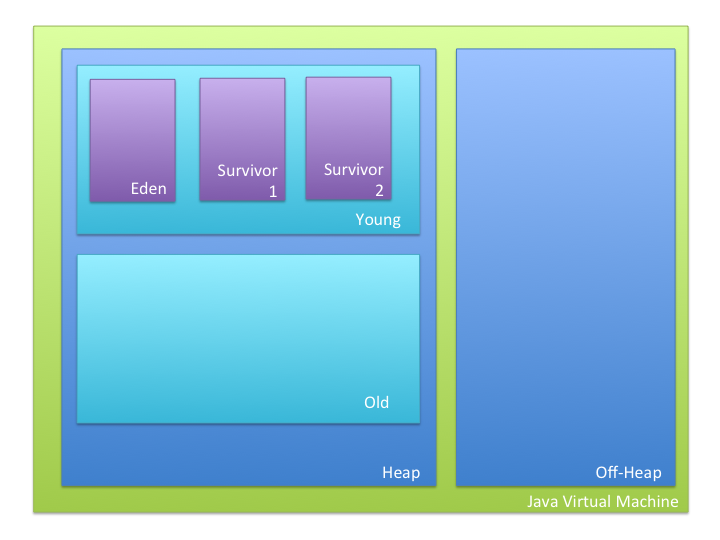 All variables start in the Eden bucket in the Young generation
All variables start in the Eden bucket in the Young generation
When it is time for garbage collection, the variables that are referenced in Eden get sent to one of the survivor buckets (empty to start). All the variables in the other survivor bucket are also moved to the once empty bucket.
Garbage collection that moves data within the young generation is fast; garbage collection that moves data between generations is slow
Garbage collection log analysis - look for tools to use to do this
Spark options :
This includes both spark task and compute vs. storage options.
spark.memory.fraction = set the maximum memory that Spark can actively use.
spark.memory.storage fraction = the minimum amount of memory that must be reserved for storage
spark.memory.executor.memoryOverhead = the executor heap size. This is added to the executor memory to determine full memory request to Yarn for each executor.
Yarn Options:
yarn.scheduler.minimum-allocation-mb: minimum memory allocated to the yarn task
yarn.scheduler.increment-allocation-mb: memory increment for yarn tasks.
yarn.nodemanager.resource.memory-mb controls the maximum sum of memory used by the containers on each node.
yarn.nodemanager.resource.cpu-vcores controls the maximum sum of cores used by the containers on each node.